شرکت چینی تنسنت (Tencent) از مدل هوش مصنوعی جدیدی به نام HunyuanWorld-Voyager رونمایی کرده که میتواند یک عکس را به ویدیوهای سهبعدی تبدیل کند.
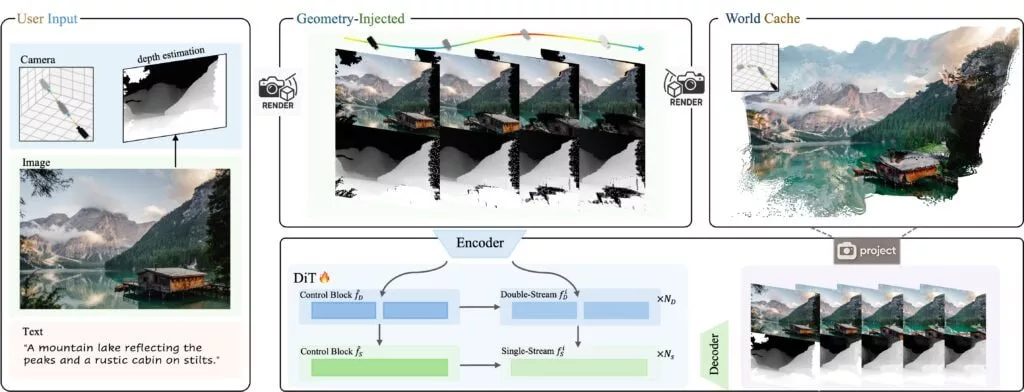
طبق گزارشهای منتشر شده، این مدل جدید به کاربران اجازه میدهد مسیر حرکت دوربین را مشخص کرده و در صحنههای مجازی که براساس عکس تولید میشود، حرکت کنند. این مدل بهطور همزمان ویدیو و دادههای عمق تولید میکند و بدون نیاز به ابزارهای مدلسازی سنتی امکان ساخت مدلهای سهبعدی را فراهم میکند.
البته نتایجی که توسط این مدل ارائه میشوند دقیقاً مدلهای سهبعدی نیستند، بلکه ویدیوهایی دوبعدی هستند که با حفظ سازگاری فضا، حرکت دوربین در یک محیط سهبعدی را شبیهسازی میکنند. همچنین مدل هر بار فقط 49 فریم (حدود دو ثانیه ویدیو) را تولید میکند، اما میتوان چندین کلیپ را به هم متصل کرد و ویدیوهای چند دقیقهای ساخت.
ورودی این مدل هوش مصنوعی فقط یک تصویر و مسیر حرکت دوربین است. حرکتهایی مانند روبهجلو، عقب، چرخش یا حرکت به طرفین نیز توسط رابط آن قابل تنظیم هستند.
تنسنت میگوید این مدل هوش مصنوعی جدید با بیش از 100 هزار کلیپ ویدیویی آموزش دیده است که شامل صحنههای واقعی و رندرهای Unreal Engine میشود. این دادهها بهصورت خودکار توسط نرمافزاری پردازش شدهاند که حرکت دوربین و عمق هر فریم را محاسبه میکند.
بااینحال، محدودیتهای معماری Transformer باعث میشود مدل بتواند فقط الگوهای دیدهشده در دادههای آموزشی را شبیهسازی کند و در موقعیتهای کاملاً جدید دچار خطا شود. به همین دلیل، Voyager در تولید چرخشهای 360 درجهای دچار اختلال میشود.
از نظر عملکرد، در بنچمارک WorldScore متعلق به دانشگاه استنفورد، Voyager بالاترین امتیاز کلی یعنی 77.62 را کسب کرده است. این مدل در کنترل اشیاء، سازگاری سبک و کیفیت خروجی عملکرد درخشانی داشته است، اما در کنترل حرکت دوربین پس از WonderWorld در رتبه دوم قرار گرفت.
برای اجرای مدل نیز به توان سختافزاری بسیار بالایی نیاز دارد، چرا که برای خروجی 540p حداقل به 60 گیگابایت حافظه گرافیکی نیاز دارد. تنسنت هماکنون وزنهای مختلف مدل را در Hugging Face منتشر کرده و کد آن را برای اجرا در دسترس قرار داده است.